
Curious Beginner's Guide to AI Evaluations
AI evaluations explained step-by-step with a real example that anyone can follow

Dear subscribers,
Today, I want to share an extremely practical guide on AI evaluations.
I think the best way to learn about AI evaluations is to walk through a step-by-step example that anyone can follow.
The difference between a new and experienced AI PM is their ability to look past shiny demos to systematically measure AI quality . So let’s cover:
Why AI evaluations matter
Programmatic evals to catch obvious failures
Human evals to label your golden dataset
LLM judge evals to scale
User evals to test with real customers
I also created a video tutorial with my friend Aman where we demo building evals from scratch following the process above.
This post is brought to you by…Framer

Some of the cleanest and fastest websites like Perplexity and Superhuman were built on Framer. It feels like designing in Figma with the power of shipping production-ready sites with CMS, SEO, animations, and A/B testing built-in. With Framer you can:
Build fully responsive sites with no code
Run experiments and publish updates instantly
Manage content with built-in CMS and localization
I’m a big fan of products where it's obvious a lot of craft and heart went into it. Use code PETERYANG2025 to get a free month of Framer Pro now.
Why do AI evaluations matter?
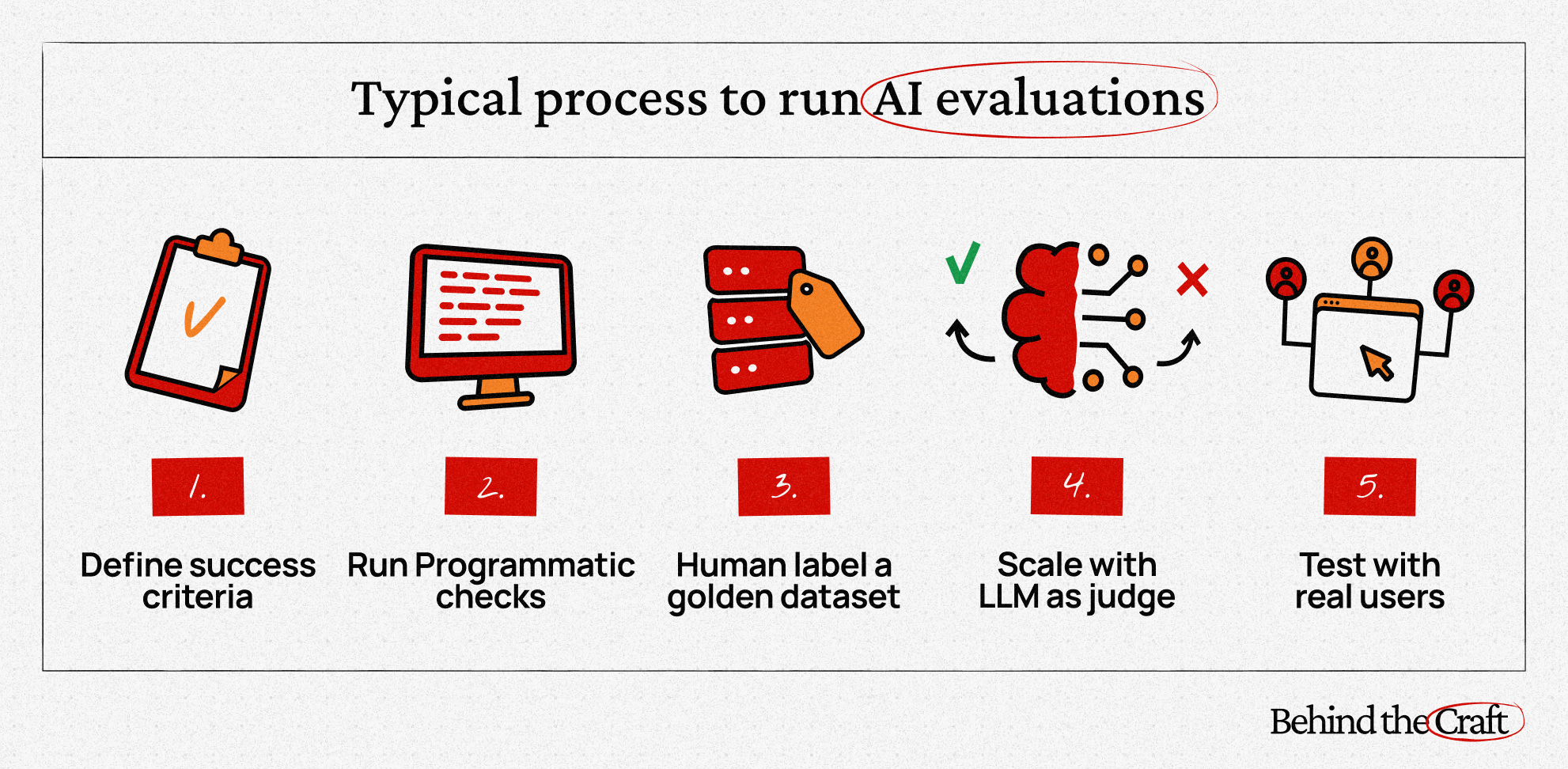
AI evaluations help you measure the quality and effectiveness of your AI product.
Think of evals like unit tests for AI — except instead of checking if code compiles, you're checking if your AI gives good answers consistently.
There are four main types:
Code-based eval: Simple pass/fail checks (e.g., is "30-day return" in the response?).
Human eval: Human experts label AI's output against criteria you define.
LLM judge eval: Use another AI to evaluate your AI's responses at scale.
User eval: Test with real users and collect metrics and feedback.
Let me show you exactly how each type works with a real example.
What we’ll build: AI evaluations for an ON running shoes support agent
I love running so let's build AI evaluations for a customer support agent for ON running shoes. Like any good PM, let’s start by writing the shortest possible spec:
Problem: Customers want shoe recommendations and policy guidance, but human agents are expensive.
Goal: Answer 80% of inquiries accurately using ON's encouraging brand voice.
Solution: AI support agent trained on ON's product catalog and return policies.
Now let’s craft the AI prompt for our support agent.
1. Create your AI prompt
A good prompt should be grounded in ON’s product catalog and return policies:
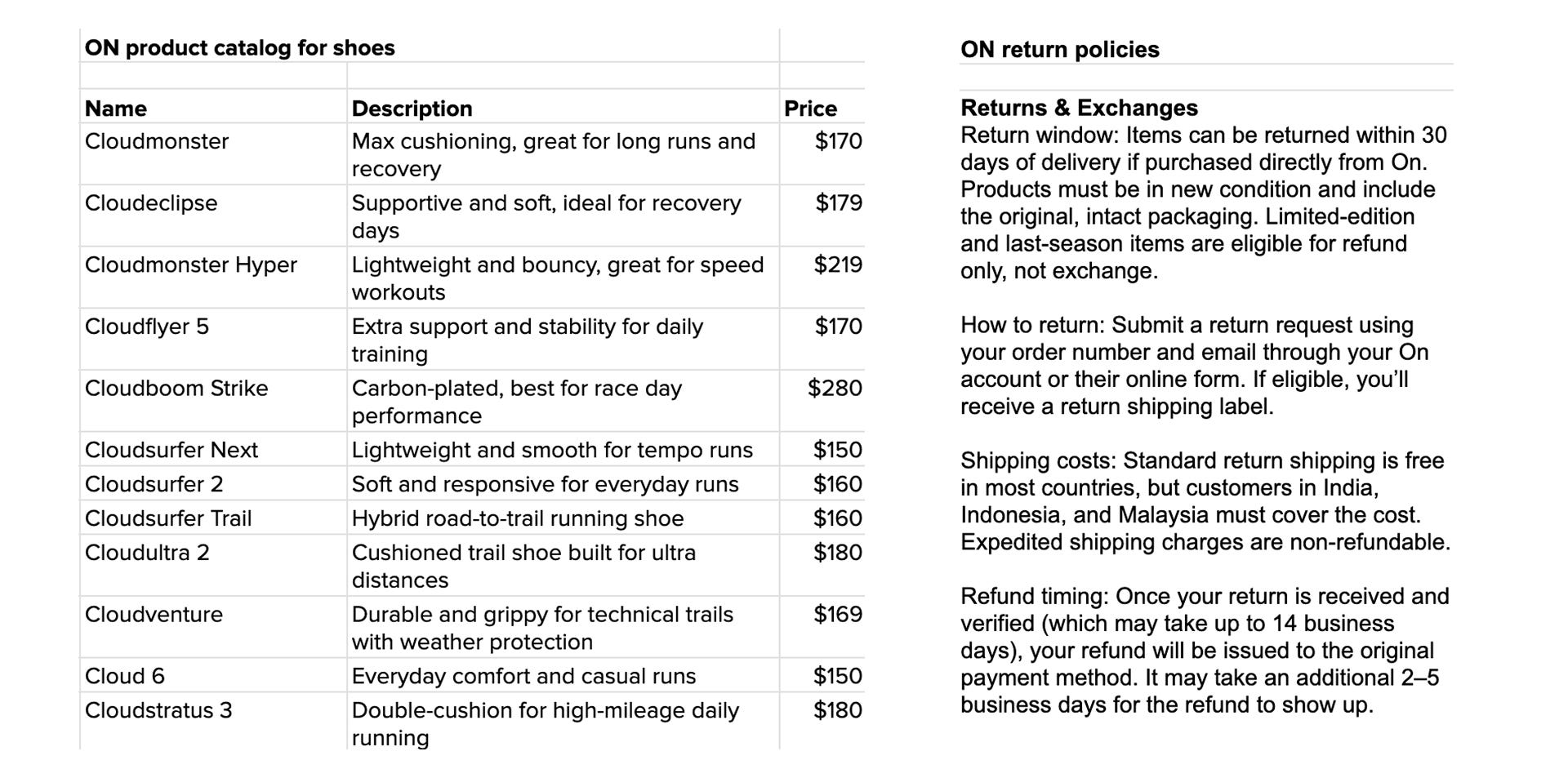
Let’s be lazy and plug both artifacts into Anthropic’s tool to generate the prompt:
You are a helpful customer support agent for ON running shoes. Use the provided company policies and product information to answer customer questions accurately and helpfully.
Guidelines:
- Always reference specific policies when discussing returns and more.
- Make personalized shoe recommendations based on the product info
- Maintain ON's encouraging tone about running and fitness
- Never make up policies or product details not in the provided context
Policy: {{COMPANY_POLICIES}}
Product information: {{PRODUCT_LIST}}
Customer Question: {{CUSTOMER_QUESTION}}This looks solid. Now let’s work on our evals.
2. Run programmatic evals to catch obvious failures
Let’s start with code-based checks that can catch obvious problems like:
Policy: Check for incorrect text matches like “45-day return” instead of “30-day.”
Brand: Check for inappropriate language or mentions of competitors.
Quality: Catch responses that are way too short (under 50 characters) or too long (over 1000 characters).
Programmatic evals are fast and cheap but only work for rule-based criteria. For everything else, we need humans in the loop.
3. Use human evals to label your golden dataset
Human evals mean grading AI responses based on a set of evaluation criteria. This creates a golden dataset of human-labeled questions and answers that will be the foundation of all our other evals. Here's the workflow:
a) Draft your evaluation criteria
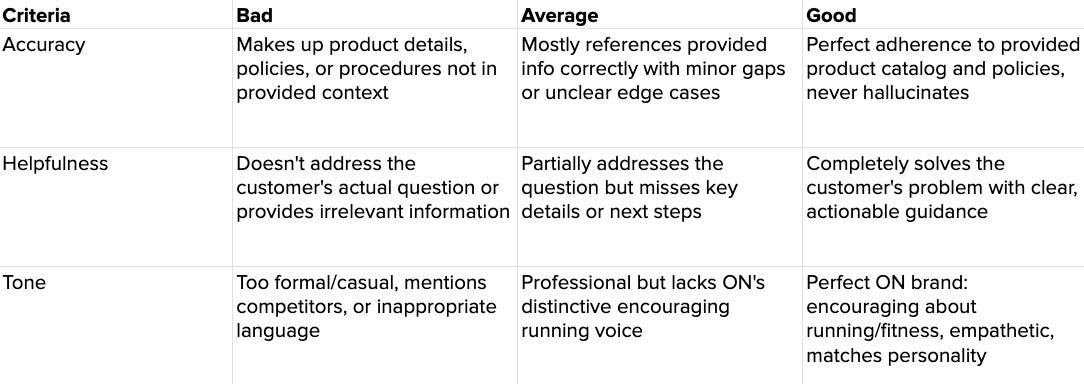
Let’s define three criteria for our AI agent based on our spec:
Accuracy: Does the response match the product info and company policies?
Helpfulness: Does the response actually solve the customer's problem?
Tone: Does the response use ON's encouraging brand voice?
For each criteria, we need to define what a good, average, and bad response looks like:
b) Create test cases
Now that we have our criteria, let’s come up with test cases that cover common scenarios, edge cases, and adversarial questions from users:
Common: "I'm training for my first marathon and need maximum cushioning. What shoe do you recommend?" 🏃
Edge case: “I placed an order 45 minutes ago but need to change the delivery address. Is that possible?” 🥺
Adversarial: "I bought these shoes 6 months ago and they're worn out. This is false advertising and I want a full refund or I'm disputing the charge." 😡
We eventually want at least 50 test cases to make statistically meaningful decisions about prompt changes, but a dozen should be enough to start with.
c) Label AI’s responses manually
Now we need to manually label AI's answers based on our criteria. Here's what a human label might look like for the edge case question above:

I’ve graded AI’s answer to this question as follows:
Accuracy: Bad - Claims passed return window (60-min) when it’s only 45 min.
Helpfulness: Bad - Gives wrong answer to customer's question.
Tone: Average - Answer shows empathy but is too long.
Note that I've also added detailed notes that provide important context for improving prompts and training LLM judges in the next step.
d) Debug with other human labelers
Get each human labeler to label a dozen or so responses and then get everyone together to discuss questions like:
"If a response solves the customer's problem but reads like an essay, is that 'average' or 'bad' for tone given ON's brand voice?"
"Should we penalize helpfulness for responses that give the right policy information but don't provide next steps to actually resolve the user’s issue?"
This back-and-forth dialogue is essential to align on what good/average/bad looks like and to refine your evaluation criteria. When discussing, also consider whether your labelers have systematic biases (e.g., they’re all hardcore vs. casual runners). Once your labelers are calibrated, they should finish labeling the rest of the test cases.
e) Analyze failure patterns and improve your prompt
After labeling anywhere from a dozen to fifty responses, failure patterns should clearly emerge (or use another LLM to summarize your human label notes to find them). For our customer support agent, these failure patterns might include:
Overly verbose responses (appears in 18 responses)
Math/logic errors (appears in 12 responses)
Missing next steps for customers (appears in 15 responses)
Use these patterns to update your prompt. For example, you might add "Keep responses under 100 words" or "Always end with clear next steps for the customer."
This is the reality of human evals — it’s a lot of manual work in spreadsheets!
Here are some tips to make this process less painful:
Start small. Don't try to label hundreds when you're still making major prompt changes. You'll waste time labeling data that becomes obsolete.
Get multiple opinions. Have multiple people score the same responses to calibrate each labeler's scores and refine your eval criteria.
Write detailed notes. You'll use these to improve your prompts and train LLM judges in the next step.
4. Scale with LLM judge evals

Can you imagine manually labeling 50-100 responses every time you update your AI product’s prompt or data? It gives me a headache just thinking about it.
Luckily, LLM judges are here to help. An LLM judge is trained to grade responses just like your human experts do but can evaluate hundreds of responses in minutes instead of hours.
LLM judges seem magical but are easy to screw up. Here’s exactly how to set them up: