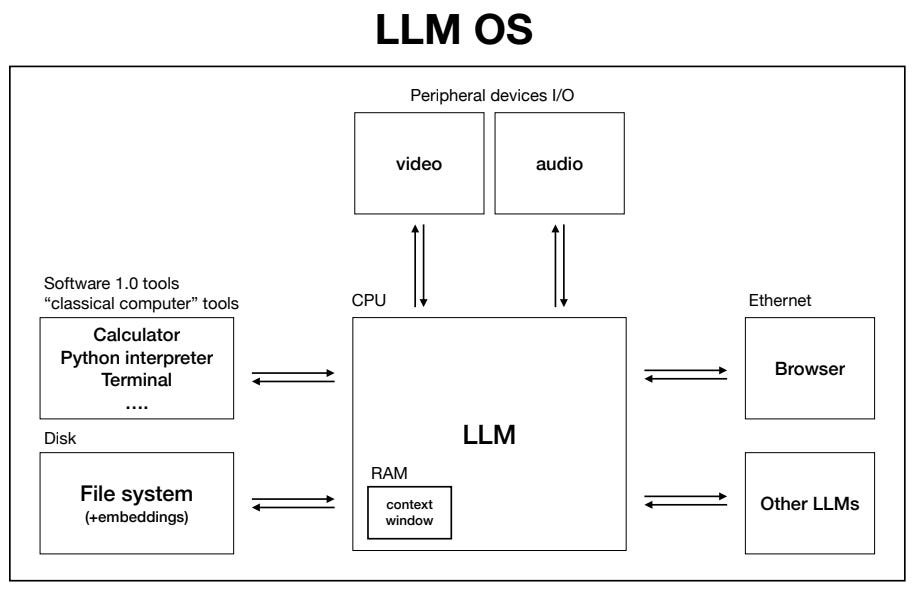
On Thanksgiving Eve, I watched a new talk by Andrej Karparthy, the famous Stanford lecturer and OpenAI founding member. He shared this image about large language models (LLMs) that blew my mind:
The best way to learn something is to explain it to others. So here’s my attempt to explain like I’m five Andrej’s talk along with my personal anecdotes on:
How LLMs work
How LLMs are trained
How LLMs can be tailored to serve a company’s specific use cases
How LLMs can evolve into the operating system of the future
I hope you enjoy this bonus edition of the newsletter!
How LLMs work
Imagine an LLM as a train laying its tracks, one word at a time
An LLM has two files:
A large file with billions of parameters for a neural network model
A tiny file with a few hundred lines of code to run the model
Think of an LLM as a “next word predictor” or a fancy autocomplete. For example, given the words “cat sat on a”, the LLM might predict “mat” with 97% probability.
LLMs can hallucinate. For example, it can invent non-existing URLs or make up math answers. Giving the LLM tools like browsing can help mitigate this, as I’ll cover later.
An example of an LLM is the open-source model LLAMA 2. You can download this model and run it locally on your computer for free.
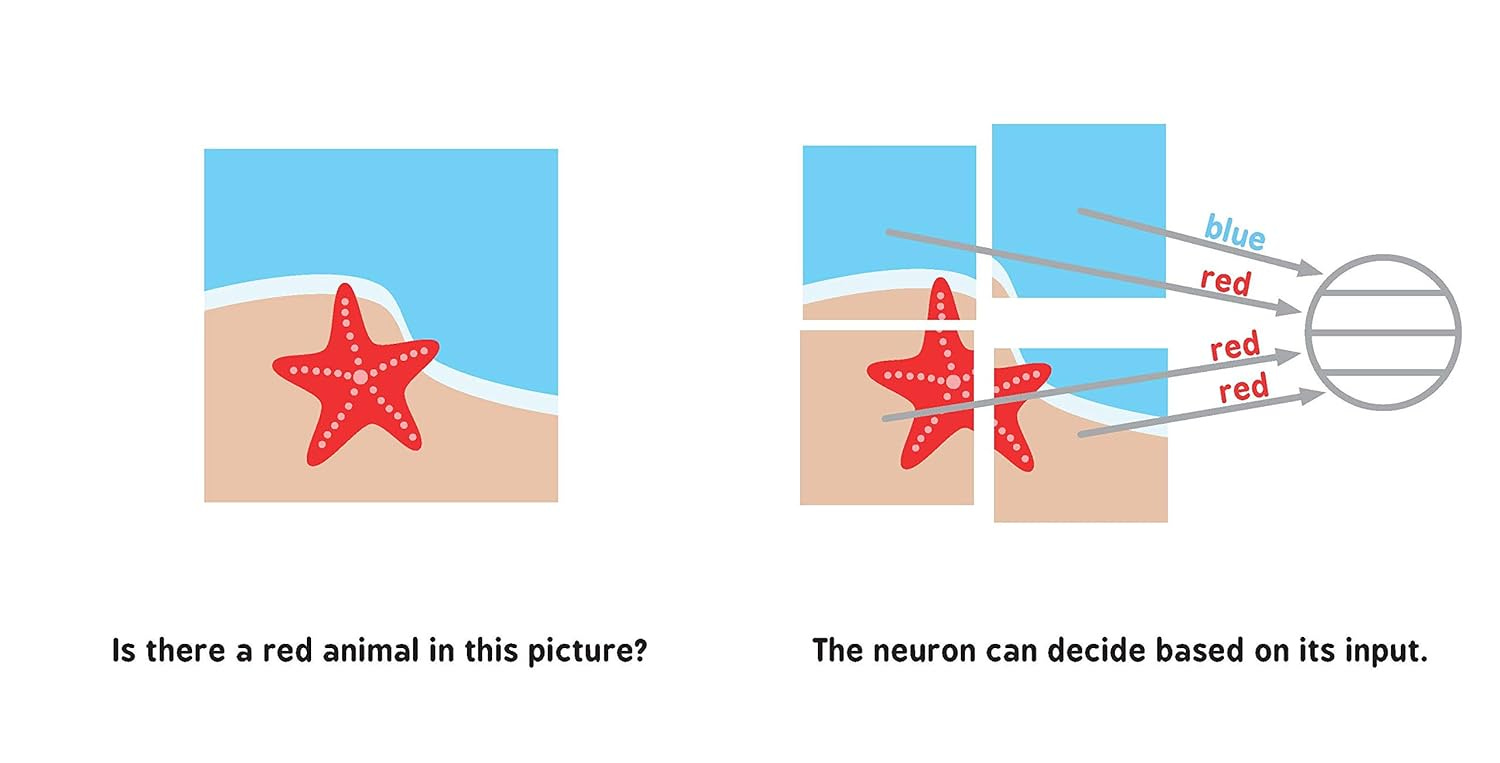
BONUS: What is a neural network?
Neural networks are like a web of neurons that make decisions and pass messages to each other. Neurons can improve their decision-making over time as they process more data.
In this example, each square is a neuron that passes a message to help another neuron decide if the picture has “red” color (from neural network for babies 😅)
Pretraining compresses the internet into a neural network:
Take 10 terabytes of text from the internet.
Compress this text into a neural network using GPUs and millions of dollars.
Obtain the base model.
Given how costly pretraining is, only a few companies (e.g., OpenAI, Anthropic, Meta, Google) can afford to train base models about once a year.
Stage 2: Finetuning
Fine-tuning is when you refine the base model for your specific use case:
Train the model on 100K+ conversations written by humans. Alternatively, given a list of questions, have humans review and pick the model’s best answers.
Obtain the fine-tuned model.
Run evaluations to refine the model further by finding bad model responses and getting humans to correct them.
Fine-tuning is much less expensive than pretraining and can be completed in a few weeks or months. You can also use LLMs themselves to evaluate another LLM’s answers, but you’ll likely still need humans to check the results. So tl:dr:
Manual human evaluation is key to fine-tuning the LLM’s output.
The difference between open-source and proprietary LLMs
As seen in the chart above, open-source models like LLAMA2 still lag behind proprietary models like GPT4 and Claude in quality. But that doesn’t mean that companies want to rely on proprietary models…
How companies can tailor LLMs for their use case
Andrej didn’t cover this section but I think it’s important to understand.
There are three ways for a company to tailor an LLM for their specific use case:
When making a custom GPT, the prompt is the "Instructions” section and RAG is the “Knowledge” files that you upload
Update the prompt: This is the easiest way to improve the LLM’s output but usually doesn’t give answers that are as personalized as the methods below.
Use retrieval augmented generation (RAG): This involves fetching info from the company’s database and adding it to the prompt.
Fine-tune the base model: This involves training the model based on human-labeled data and feedback, as we discussed above.
From my conversations with various companies, most of them are:
Deploying proprietary models in production (e.g., GPT3.5 or 4) and using prompt engineering and RAG to improve their output.
Fine-tuning open source models at the same time.
Companies are pursuing both paths at once because they want to replace their dependency on proprietary models with their own open-source models.
As we’ve seen from what happened at OpenAI last week, platform risk is very real.
How LLMs can be tailored to serve a company’s specific use cases
Let’s go back to this image from Andrej’s talk:
Here’s how LLMs can evolve from next-word predictors to a full operating system:
1. LLMs can use tools
ChatGPT can use tools like browsing to avoid hallucinations
If I ask you “What happened to OpenAI last week,” you’ll probably search for the most recent news articles on Google. We can also give this browsing tool to LLMs:
We can write a prompt that’ll help an LLM recognize when users want recent info.
The LLM can then use a search engine like Bing to pull up a list of recent links.
The LLM can copy each link’s full text into its context window and summarize.
LLMs can also use tools like calculators and RAG to get more reliable information and avoid hallucinations.
2. LLMs can go multimodal
A funny exchange that I had with Elon recently on X
Think of ChatGPT like a brain that can use the following tools:
Eyes: It can see through image recognition and your phone’s camera.
Ears: It can listen through your phone’s microphone.
Voice: It can speak through text to voice.
Hands: It can “draw” any image given a text prompt.
Imagine a cute robot (Astro Boy?) powered by an LLM — I’d love to buy one for my kids someday.
3. Can LLMs think fast and slow?
I only enjoyed the first chapter of Daniel’s book to be honest
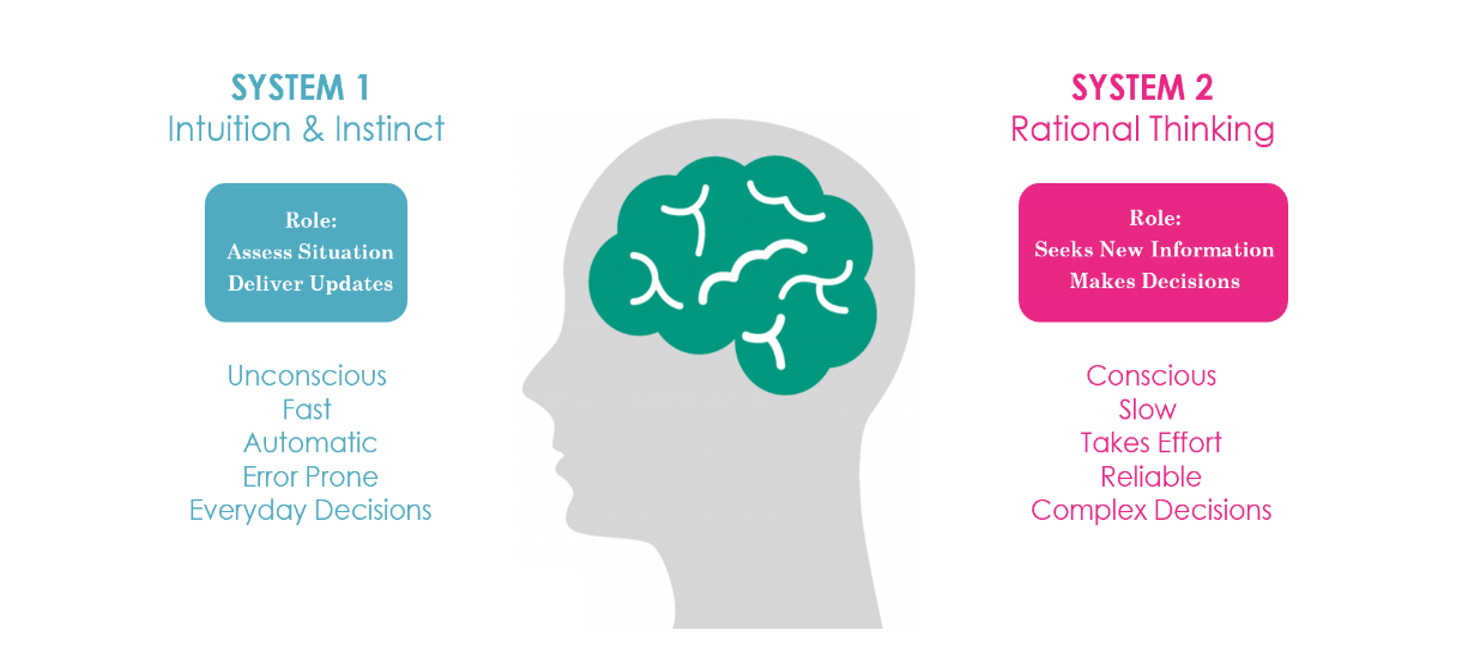
Thinking Fast and Slow is a popular book by psychologist Daniel Kahneman. The thesis of the book is that humans solve problems using two different systems:
System 1 (fast): Makes quick judgments based on intuition.
System 2 (slow): Makes rational decisions by processing info carefully.
Today, LLMs can only do system 1 thinking (they’re next-word predictors after all). However, there are papers studying how LLMs can do system 2 thinking using “tree of thought” and other methods.
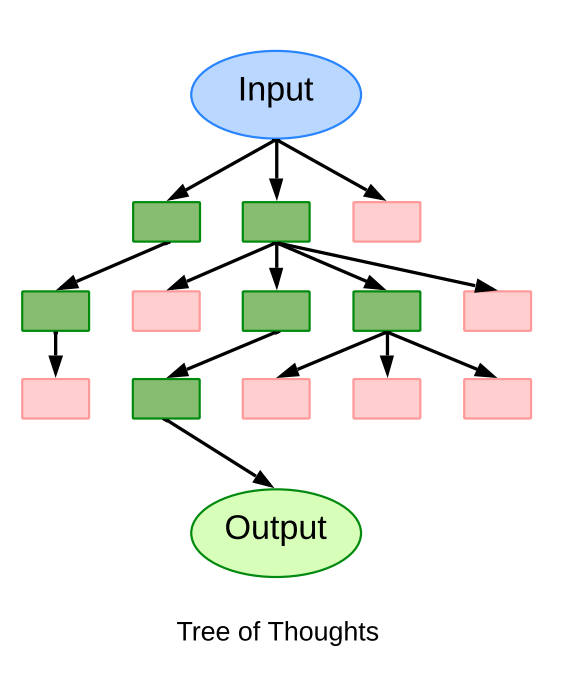
BONUS: What is tree of thought?
Tree of thought is a method that’s being explored to let LLMs mimic rational thinking. It lets LLMs branch out their thinking and consider multiple options and consequences before making a decision.
Sadly there is no tree of thought for babies book but here’s a great research paper on the topic
4. Can LLMs improve themselves?
AlphaGo beat the best Go player Lee Sedol back in 2016
As we discussed, LLMs are fine-tuned through manual human training and evaluation. But in narrow use cases where the objective is clear, LLMs might become better at the task than even the best humans.
A great non-LLM example from Andrej’s talk is Google’s AlphaGo, an AI for the game Go. Here’s the team on how AlphaGo eventually surpassed the best human players:
“It played itself millions and millions of times and each time got incrementally slightly better. It learns from its mistakes.”
5. Can LLMs work with other LLMs?
Since OpenAI introduced the ability to create custom GPTs, I’ve made GPTs for:
Editing social posts
Writing newsletter headlines
Generating Apple-style marketing images
and more…
I’ll share links to these custom GPTs in a future post. For now, I want to point out that:
With custom GPTs, it almost feels like I’ve hired AI agents to do work for me.
Now imagine giving these agents the ability to talk to each other. Two examples:
You can use GPT4 to evaluate your fine-tuned open-source model’s answers.
You can use Codegen, a startup from my friend that uses multiple GPT agents to turn a JIRA ticket into a PR in minutes.
How LLMs can evolve into the operating system of the future
To recap, here’s how LLMs can become the operating systems of the future:
CPU: The core LLM.
RAM: The LLM can save the prompt or any RAG files in its context window.
Ethernet: The LLM can explore the internet and talk to other LLMs.
Disk: The LLM can retrieve files for its context window using RAG.
Applications: The LLM can use tools like calculators and Python interpreters.
Devices: The LLM can see, hear, speak, and more through peripheral devices.
I hope this guide makes you as excited for the future as I am. If you haven’t already, you should definitely check out Andrej’s full one-hour talk and slides.
Enjoyed this post? Give it a ❤️ so I know to write similar posts in the future.