
Building AI Products (Part 2): Prompting, Retrieval Augmented Generation, and Fine-Tuning Explained
A step by step walkthrough with examples on how to personalize AI's responses

Dear subscribers,
Today, I want to share part 2 of a 3-part guide on building a generative AI product.
Your AI product is only as good as your data.
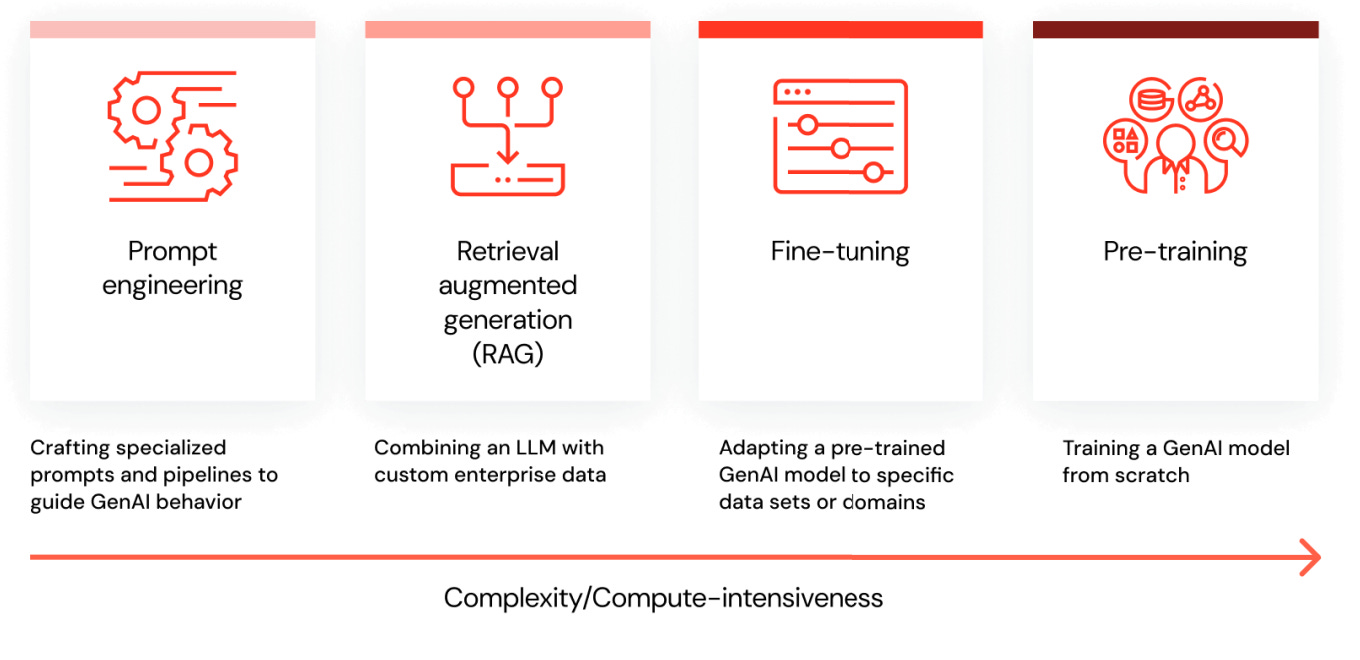
In the sections below, we’ll cover how you can personalize AI’s response using:
Prompt engineering
Retrieval augmented generation (RAG)
Fine-tuning
Pre-training
If you missed it, part 1 covered the 3P framework to select AI use cases and the right model. Part 3 will focus on evaluation and deployment. Let’s dive in.

This post is brought to you by…Sidebar

Being a tech leader can be lonely. Sidebar matches you with a vetted group of peers who can help you achieve the desired outcomes. It's like a personal board of directors who are there when you need it most.
93% of members say that Sidebar has been a game-changer in helping them get a promotion, launch a new company, or find a new role. Join Sidebar to connect with other members, including executives, Oscar winners, and even Olympians.
Four ways to personalize AI’s response
Prompt engineering

Prompt engineering is a fancy phrase for updating a static prompt to produce a better AI response. I’ve covered crafting a great prompt before, so let’s focus instead on why:
Prompt engineering is perfect for prototyping.
Here’s how I like to prototype using prompts alone:
Manually pull and clean data for a few customers.
Write out your ideal AI response based on the data.
Write a prompt and include the data from step 1. Use a best-in-class AI model (e.g., Claude) and iterate until AI’s response closely matches your ideal response. Even better, show the response to customers and iterate with them.
Example: Summarizing online reviews
Let’s say you want to prototype an AI product that summarizes customer reviews:

You should start by manually pulling raw customer reviews for several merchants. Then, manually write what you think the ideal AI response should look like given this data. Finally, iterate on the prompt with merchants and shoppers to get as close to your ideal response as possible. The final prompt might look like something like this:
Summarize the key points from these customer reviews in 2-3 sentences. Focus on:
Overall sentiment (what customers generally say)
Key attributes that customers appreciate or have complaints about
Mention specific details or any standout features
Use natural language. For example:
"Customers say [overall sentiment]. They appreciate [key attributes]. [Specific details] are mentioned. [Standout feature] is also highlighted."
Now, please generate a summary based on these reviews (Copy and paste raw reviews)
Let’s face it:
Prompting alone won't differentiate your AI product from base models.
However, prompting will help you quickly understand how close you can get to your desired AI response with proprietary data from a few customers.
That’ll help you decide whether the next two methods are worth pursuing.
Retrieval augmented generation (RAG)

Proprietary data is the secret sauce for many AI products, and retrieval augmented generation (RAG) is a great way to include up-to-date data in your prompts at scale.
RAG can significantly enhance the accuracy of AI’s response by dynamically inserting recent data in your prompt.
Before we dive into RAG implementation, let's define some key concepts:
Embedding: Converting text (or other data) into a series of numbers (vectors) representing its meaning. For instance, "dog" and "puppy" would have similar embeddings, while "cat" would be different.
Similarity search: Find the most related info by comparing embeddings (distance between numbers). For example, searching for "loyal pet" might return "dog" and "horse" as they're closer in meaning than "goldfish."
Vector database: Stores and retrieves embeddings based on semantic meaning. A search for "furry house pet" might return "cat" and "rabbit," even if those exact words aren't in their descriptions.
Given this info, Here’s how RAG works for AI products:
Clean up and process your data using an AI framework like LangChain
Convert your data into embeddings and store them in a vector database.
When a user submits a query, use similarity search to find the relevant info.
Add the user’s query and relevant info to your prompt.
Continuously update your database with new information to keep responses fresh.
Example: Answering technical documentation questions
Let’s say you want to build an AI assistant to answer technical questions about your product based on your documentation.
You should start by converting your documentation into embeddings and storing them in a vector database. When a user asks a question, you can use a similarity search to find the most relevant documentation. Finally, you can craft a prompt that includes both the user question and the documentation:
You are a helpful AI assistant for [product name]. Use the following info from our technical documentation to answer the user's question. If the info provided doesn't fully answer the question, say so and suggest where they might find more information.
User question: [Insert user's question here]
Relevant documentation: [Insert retrieved information here]
Fine-tuning

While RAG excels at including up-to-date information in your prompt, fine-tuning is ideal for optimizing performance on specific, well-defined tasks where you have great training data. Specifically:
Fine-tuning requires having a large, quality dataset of input-output pairs.
Here's a typical fine-tuning process:
Prepare thousands of input-output pairs that represent your ideal AI interactions.
Select a base model and tune it on your dataset using an AI framework. This involves showing the model your examples repeatedly so that it can adjust its weights to predict the desired output better.
Evaluate and refine the model's performance as needed (we’ll cover this in part 3).
The quality and diversity of your fine-tuning dataset are crucial. To create a robust model, your data needs to represent a wide range of scenarios and edge cases.
Example: E-commerce customer support agent
Let's say you want to build a customer support agent to handle inquiries about orders and returns. You could fine-tune a base model using thousands of real customer service conversations from your company. An example conversation chunk might be:
Customer: "I ordered a blue sweater last week but received a red one instead."
Customer support agent: "I apologize! We can send you the blue sweater at no additional cost or arrange a refund. What do you prefer?”
By providing thousands of quality examples, you’re teaching the model to respond in the right style and with the specific knowledge of your customer service team.
Pre-training
Pre-training involves building a new AI model from scratch.
99% of the time, you should not be pre-training a model.
You should only consider it when you have millions of proprietary data for a specific domain. Pre-training is very expensive and time-consuming. Here’s how it works:
Collect a massive amount of data (millions) relevant to your domain.
Set up training infrastructure (e.g., GPUs) to handle the load.
Train the model from scratch on your data, which can take weeks or months.
Optionally fine-tune the pre-trained model for more specific tasks.
Example: Predicting protein structures

A real-world example of pre-training in action is DeepMind's AlphaFold, which aims to predict the structure and interactions of all of life’s molecules.
DeepMind gathered a massive dataset of known structures from the Protein Data Bank and related databases. The model was then pre-trained on the collected data to learn general principles of protein folding and structure.
The result was a model that could accurately predict protein structures, even for previously unseen proteins. This helped with drug discovery, understanding diseases, and more.
Wrap up

Many AI products combine prompt engineering, RAG, and sometimes fine-tuning to achieve their goals. A typical path that I’ve seen is:
Start with prompt engineering to quickly prototype and validate your idea.
Consider RAG to include up-to-date proprietary data in your AI response.
Invest in fine-tuning if you have a large, specialized dataset of examples.
Avoid pre-training unless you want to invest millions in a specialized model.
In the final part of this series, we'll discuss arguably the most important (and painful) step: evaluating and deploying your AI product. Stay tuned!